
ZFS 在 Linux 上越来越常见:它把文件系统 + 软件 RAID + 校验 + 快照/发送接收打包成一个整体,尤其适合对数据可靠性有要求的场景(虚拟化、数据库、备份仓库等)。
这篇文章记录我在 Ubuntu 22.04 上用两块盘搭建 ZFS Mirror(等价 RAID1)、做 fio 性能压测,并进行一次“拔盘换盘”的灾难演练过程。过程中也踩到了一些典型坑:比如 设备命名漂移(sdb/sdc 交换)、以及 4K 随机读压测结果“离谱地慢/离谱地快”的原因,需要指出的是ZFS带来高级特性的同时,也会降低读写性能。
⚠️提示:本文包含清盘/创建 zpool 的危险命令,请勿在生产环境盲目复制。
前言:ZFS 和 mdadm的区别
| 维度 | ZFS(mirror) | mdadm(RAID1)+ ext4/xfs |
|---|---|---|
| 定位 | “RAID + 卷管理 + 文件系统”一体化 | “块设备 RAID” + 上层文件系统组合 |
| 数据完整性(防 silent corruption) | ✅ 端到端校验(checksum),可发现静默错误;镜像下可自愈 | ❌ 无端到端校验(一般读到啥就信啥);镜像只保证副本,不保证正确性 |
| RAID1 读性能 | ✅ 可做镜像读分担,但效果受实现/调度/负载特征影响 | ✅ 通常很容易做到两盘并行读,IOPS 更“直出” |
| RAID1 写性能 | ⚠️ COW + 事务组,随机小写/同步写更容易放大开销(可调优/靠硬件改善) | ✅ 双写开销可预期,路径短、开销小(但写不会翻倍) |
| 4K 随机读(你这类场景) | ⚠️ 早期在资源不足/参数不合适时可能明显偏低;给足 vCPU/RAM 后会改善 | ✅ 往往更容易跑满底层能力,表现稳定 |
| 4K 随机写 | ⚠️ 可能更吃 CPU/内存;尾延迟更敏感(sync 写尤其明显) | ✅ 机制简单,通常更省心;尾延迟主要看盘/后端阵列/GC |
| 顺序吞吐 | ✅ 常见场景很强;lz4 压缩有时还能“越压越快” | ✅ 强且稳定,瓶颈更容易定位(盘/控制器/队列) |
| 快照/克隆 | ✅ 原生快照、克隆、回滚 | ❌ 需要 LVM/btrfs/应用层方案配合 |
| 备份/迁移 | ✅ zfs send/receive 非常强(增量迁移/复制) | ⚠️ 依赖 rsync/镜像/备份软件;一致性需额外设计 |
| 在线扩容 | ✅ 可加 vdev(注意规划:vdev 是性能/可靠性基本单元) | ✅ 可 grow/reshape(风险与耗时视阵列而定) |
| Scrub / 巡检 | ✅ 原生 scrub,能提前暴露潜在坏块并修复(镜像) | ⚠️ 一般靠 RAID check/文件系统工具,无法做到端到端校验修复 |
| 故障替换/重建 | ✅ zpool replace + resilver;可按需重建(看脏块) | ✅ mdadm --add 触发 resync;通常是全盘重建 |
| 资源消耗 | ⚠️ 更吃 RAM/CPU(ARC、校验、COW、元数据) | ✅ 更轻量 |
| 运维复杂度 | ⚠️ 概念多、参数多,需要理解“为什么”才能调得好 | ✅ 经典套路,资料多、团队通用性强 |
| 适合数据库/虚拟化(高 IO) | ✅ 适合,但建议足资源+正确调参;并尽量减少“多层存储叠加” | ✅ 很适合,尤其在虚拟化/后端阵列环境下更稳 |
| “追求可靠性和安全性” | ✅ 强项:数据完整性、自愈、快照体系 | ⚠️ 可靠性主要体现在“掉盘可用”,但不擅长发现静默错误 |
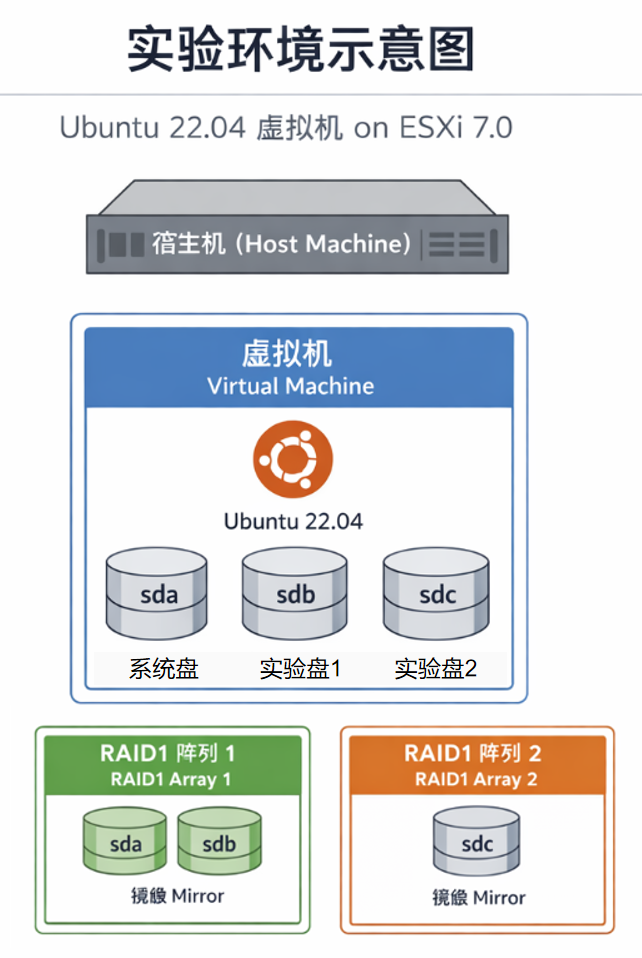
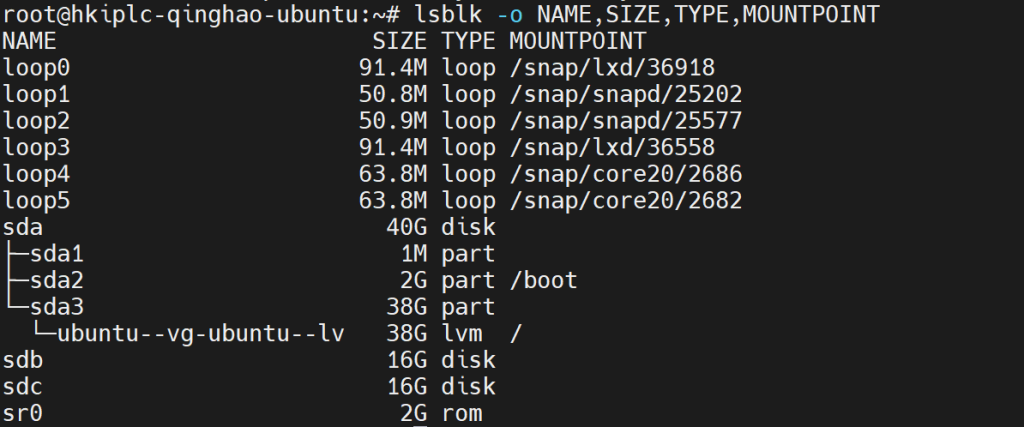
1.实验环境:
系统:Ubuntu 22.04,ESXi7.0下虚拟机
磁盘:sda为系统盘,sdb、sdc为实验盘(16GB),其中sda、sdb挂载在宿主机RAID1阵列1下,sdc挂载在宿主机RAID1阵列2下。
2.安装ZFS:
apt update
apt install -y zfsutils-linux2.1 用 by-path 锁定磁盘(避免 sdb/sdc 未来对调)
在虚拟化/热插拔环境里,/dev/sdb、/dev/sdc 不保证永远指向同一块盘。建议用稳定路径,例如 by-path 或 by-id。
ls -l /dev/disk/by-path/
#sdb = /dev/disk/by-path/pci-0000:00:10.0-scsi-0:0:1:0
#sdc = /dev/disk/by-path/pci-0000:00:10.0-scsi-0:0:2:0后续创建 zpool、replace 都用这两个路径,能显著减少“盘位换了导致操作错盘”的风险。
2.2 创建 zpool(ZFS Mirror / RAID1)
下面创建一个名为 tank 的存储池,vdev 类型为 mirror,挂载点是 /tank。
zpool create -f -o ashift=12 \
-O compression=lz4 \
-O atime=off \
-O xattr=sa \
-O mountpoint=/tank \
tank mirror \
/dev/disk/by-path/pci-0000:00:10.0-scsi-0:0:1:0 \
/dev/disk/by-path/pci-0000:00:10.0-scsi-0:0:2:0参数说明(简要):
ashift=12:按 4K 扇区对齐(SSD/现代盘基本都推荐)compression=lz4:轻量压缩,通常“收益大、负担小”atime=off:关闭访问时间更新,减少额外写xattr=sa:xattr 用 SA 存储,性能更好
2.3 验证
zpool status -v tank
zfs list
df -h | grep tank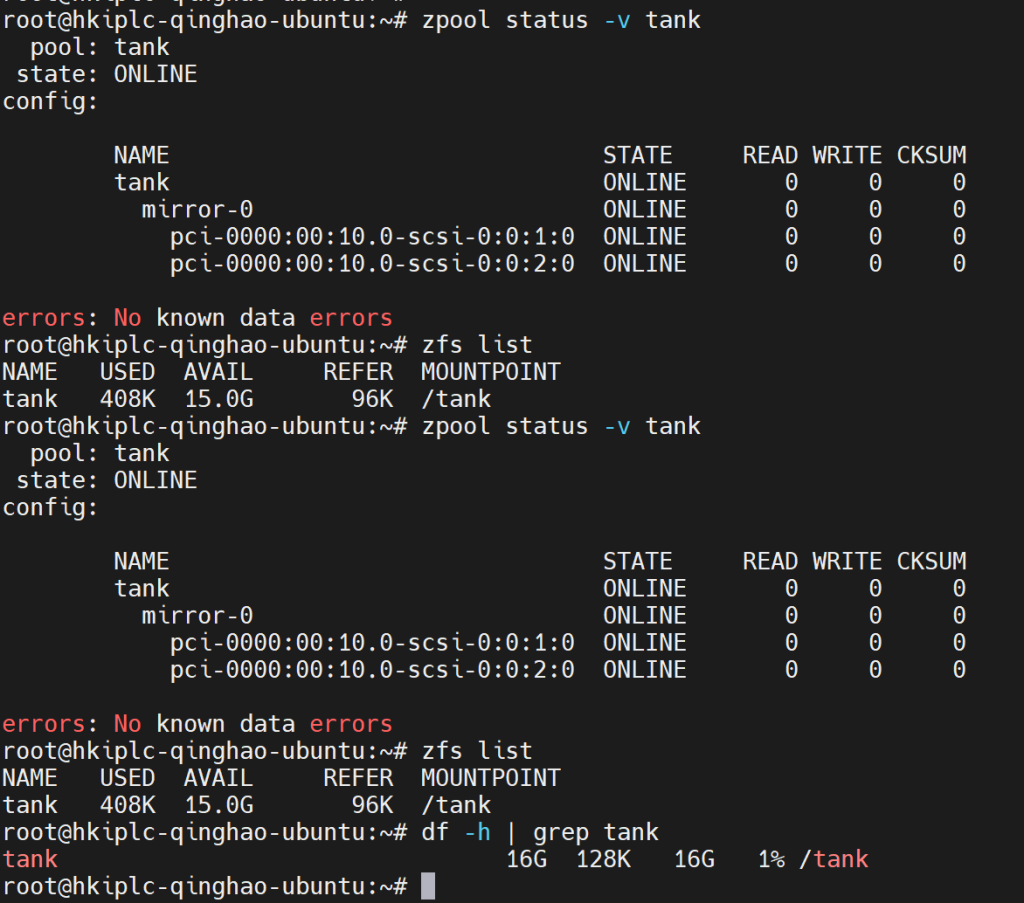
应该能看到 tank 的 mirror-0 两块盘都处于 ONLINE 状态,且 /tank 正常挂载。
3.性能测试
3.1安装测试软件
apt update
apt install -y fio sysstat建一个数据集,专门用来测试
zfs create tank/bench
zfs set compression=off tank/bench
zfs set atime=off tank/bench
mkdir -p /tank/benchA) 顺序写(大块写,像备份/镜像写入)
fio --name=seqwrite --directory=/tank/bench \
--rw=write --bs=1M --size=8G \
--ioengine=libaio --direct=1 --iodepth=32 --numjobs=1 \
--time_based --runtime=60 --group_reportingB) 顺序读(大块读)
fio --name=seqread --directory=/tank/bench \
--rw=read --bs=1M --size=8G \
--ioengine=libaio --direct=1 --iodepth=32 --numjobs=1 \
--time_based --runtime=60 --group_reportingC) 随机 4K 读(数据库/虚拟化最关心的 IOPS)
fio --name=randread4k --directory=/tank/bench \
--rw=randread --bs=4k --size=2G \
--ioengine=libaio --direct=1 --iodepth=64 --numjobs=4 \
--time_based --runtime=60 --group_reporting --randrepeat=0 --norandommap
D) 随机 4K 写(更接近数据库写压力)
fio --name=randwrite4k --directory=/tank/bench \
--rw=randwrite --bs=4k --size=2G \
--ioengine=libaio --direct=1 --iodepth=64 --numjobs=4 \
--time_based --runtime=60 --group_reporting --randrepeat=0 --norandommap
4. 灾难演练:模拟掉盘 + 换盘 + 恢复 Mirror
4.1 物理拔出一块盘后,先看 zpool 状态
zpool status -v tank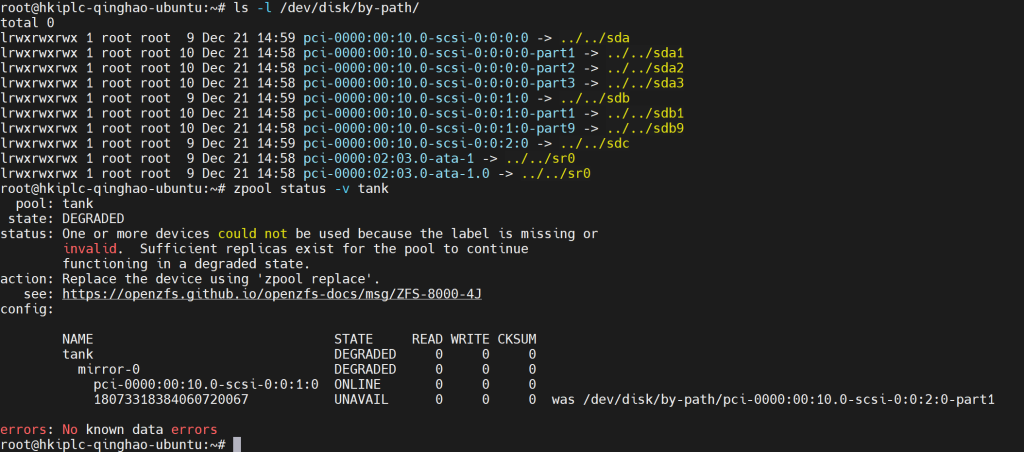
关键信息都在 zpool status 里:
- tank / mirror-0:DEGRADED
- 还活着的一侧:pci-0000:00:10.0-scsi-0:0:1:0 ONLINE
- 掉掉的一侧:18073318384060720067 UNAVAIL
- 并且提示:was /dev/disk/by-path/…-scsi-0:0:2:0-part1
- => 说明 原来的 sdc 那侧(part1)标签丢了/盘被替换了,ZFS 认不出它了。
4.2 确认新盘对应的 by-path 路径
换盘后再次看:
- /dev/disk/by-path/pci-0000:00:10.0-scsi-0:0:2:0 -> /dev/sdc
- 这正好就是新盘所在槽位。下一步就是 replace。
你会发现原来那个槽位的路径还在,但指向了新的 /dev/sdc(这就是我们前面坚持用 by-path 的价值)。
4.3 用 zpool replace 替换坏成员并触发 resilver
把 “坏成员” 替换成你现在的新盘(刚才整盘 by-path拿到的新盘):
zpool replace -f tank \
18073318384060720067 \
/dev/disk/by-path/pci-0000:00:10.0-scsi-0:0:2:04.4 观察重建进度
watch -n 1 zpool status -v tank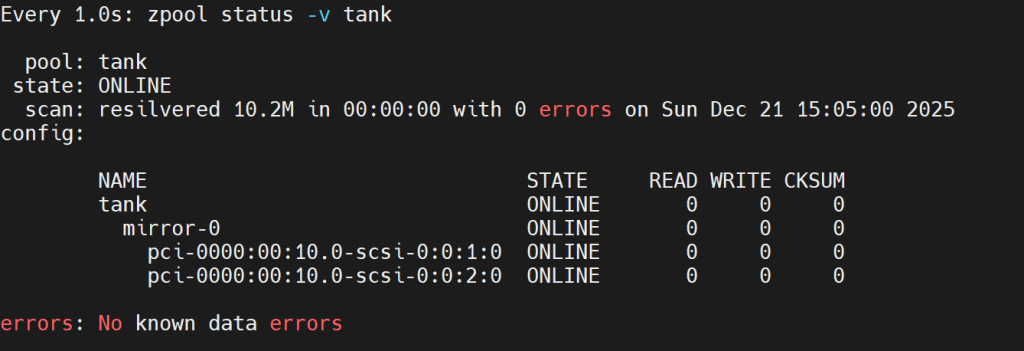
从输出可以确认:
pool: tankONLINEmirror-0两块盘都 ONLINEscan: resilvered 10.2M ... with 0 errors:重建完成且无错误errors: No known data errors
4.5 验证可读可写(演练完成后的 sanity check)
ls -lah /tank
dd if=/dev/urandom of=/tank/post_recover.bin bs=1M count=128 status=progress
sync
sha256sum /tank/post_recover.bin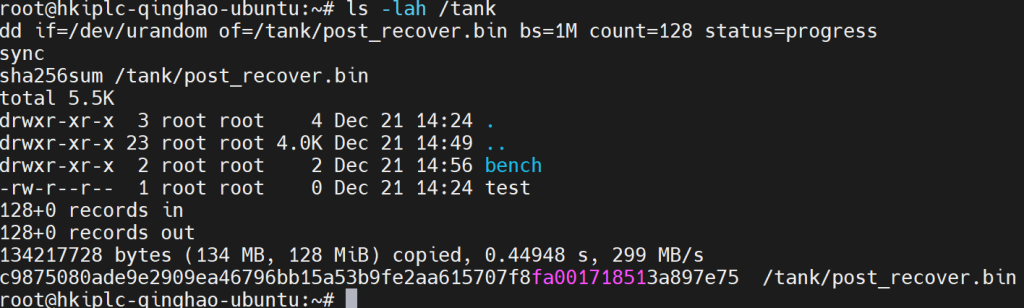
附录:我踩到的坑:ZFS 上 4K 随机读“怎么这么慢/怎么突然这么快?”
这是 ZFS 压测里非常常见的误区,尤其是数据库/虚拟化场景。
坑 1:recordsize=128K 会让 4K 随机读出现“读放大”
ZFS 文件系统按 recordsize(默认 128K)组织数据块。你发起 4K 随机读时,底层可能需要把更大的 record 读出来再切 4K 给你,导致:
- fio 看到的 4K IOPS 变低
- 实际底层读的数据量变大
解决思路:针对数据库小块随机 IO,单独建 dataset 调整 recordsize(例如 16K/8K/4K),再测:
zfs create -o compression=off -o atime=off -o recordsize=16K tank/bench16k
zfs create -o compression=off -o atime=off -o recordsize=4K tank/bench4k坑 2:加内存/CPU 后 IOPS “暴涨”,多半是 ARC 命中(缓存喂出来的)
我把 VM 从 2C/4G 调到 12C/8G 后,fio 的 4K 读 IOPS 从几万直接飙到十万级。
原因:ZFS 的 ARC 会用内存做缓存,测试文件如果不大(比如 4G),很容易被 ARC 装下。即便你用 --direct=1 --invalidate=1,也只能尽量绕过 Linux 页缓存,不一定能阻止 ZFS ARC 命中。
验证 ARC 是否“顶满”可以看:
grep -E 'size|c_max|hits|misses' /proc/spl/kstat/zfs/arcstats | head -n 30如何测“真实盘能力”(绕开 ARC 数据缓存)
把 dataset 的 primarycache 临时改为 metadata(只缓存元数据,不缓存数据),再跑 fio,就更接近真实后端能力:
zfs set primarycache=metadata tank/bench16kfio --name=rr4k_tank_rs16k_nocache --filename=/tank/bench16k/fiofile \
--rw=randread --bs=4k --size=4G \
--ioengine=libaio --direct=1 --iodepth=64 --numjobs=4 \
--time_based --runtime=60 --group_reporting \
--randrepeat=0 --norandommap --invalidate=1
测完记得恢复:
zfs set primarycache=all tank/bench16k坑3: ZFS(/tank)和主盘(/test,sda)4K 随机读差异巨大
这次压测里我遇到一个非常反直觉的现象:同一台 VM、同样的 fio 参数,主盘 sda 上的随机读 IOPS 能到十万级,而 ZFS mirror(/tank)在某些情况下只有一两万级,甚至更低。
1)主盘(sda /test)4K randread:~135k IOPS
我在 /test(位于 sda)上用 20G 工作集做随机 4K 读,尽量绕开来宾页缓存(drop_caches + --direct=1 --invalidate=1),结果非常稳定:
- fio:IOPS ≈ 135k,BW ≈ 528MiB/s
- 平均延迟:clat ≈ 1.88ms
- iostat 同步确认:
r/s≈135k、rareq-sz=4K、r_await≈1.85ms、%util=100%
这说明:至少在 VM 视角下,sda 这条虚拟盘路径确实能提供非常高的 4K 随机读吞吐,不是“测到了缓存假象”。
2)ZFS mirror(/tank)在“真实 miss”场景:~16k IOPS
为了测 ZFS 在“真实后端”上的能力,我把压测 dataset 的数据缓存关掉,只保留元数据缓存:
zfs set primarycache=metadata tank/bench16k同样的 4K randread(recordsize=16K)立刻掉到:
- fio:IOPS ≈ 16k,BW ≈ 62.6MiB/s
- 平均延迟:clat ≈ 15.7ms
这个结果非常典型:当 ARC(ZFS 内存缓存)不再喂数据时,ZFS mirror 的随机读性能明显下降,延迟也显著上升。
这不是 “ZFS 一定慢”,而可能“测试方式 + 访问路径”共同决定的结果:
(1) recordsize 读放大(默认 128K 对 4K 随机读不友好)
ZFS dataset 默认 recordsize=128K。当应用以 4K 为单位随机读时,底层可能会按 recordsize 组织数据,出现读放大,导致“有效 4K IOPS”明显变低。
我把 dataset 改成 recordsize=16K/4K 后,4K 随机读 IOPS 立即有明显提升。
(2) ARC 缓存会让结果“突然变得离谱快”
我把 VM 内存从 4GB 提升到 8GB 后,ZFS 的 ARC 很容易把 4GB 的测试文件装进缓存里,导致 4K 随机读 IOPS 暴涨到十万级。
但这属于“命中缓存”的表现,并不能代表后端磁盘阵列的真实能力。
(3) ZFS 数据路径更重:校验/元数据/调度开销
相较 ext4/xfs 这类传统文件系统,ZFS 的读路径包含校验、对象/块管理、vdev 调度等额外开销。
当缓存 miss 需要真正下发 I/O 时,这些开销会更明显。
(4) Mirror 读调度 + 虚拟化存储路径差异/tank 是 mirror,理论上读可以从任一侧取数据,但如果两块盘来自不同 RAID 组、不同队列/延迟特性,mirror 的读调度可能出现“某一侧拖后腿”的情况。
我这个环境里,sdb/sdc 实际来自宿主机不同 RAID1 组,确实观察到性能差异。
(5) 对照表(非严谨实验)
| 位置/模式 | 关键设置 | IOPS | 带宽 | 平均延迟(clat) | 备注 |
|---|---|---|---|---|---|
| /test(sda)冷读 | size=20G,drop_caches,direct=1 | ~135k | ~528MiB/s | ~1.88ms | iostat 同步确认 r/s≈135k、rareq-sz=4K |
| /tank(ZFS,rs=16K,ARC 热) | primarycache=all,VM升到 12C/8G | ~104k | ~407MiB/s | ~2.4ms | 明显是 ARC 命中加速后的水平 |
| /tank(ZFS,rs=4K,ARC 热) | primarycache=all | ~59k | ~231MiB/s | ~4.25ms | 小 recordsize 反而更“重”,CPU/元数据更忙 |
| /tank(ZFS,rs=16K,冷读) | primarycache=metadata(禁数据缓存) | ~16k | ~62.6MiB/s | ~15.7ms | 这更接近“真实后端 + ZFS mirror”的能力 |
| /tank(ZFS 默认 rs=128K) | 未调 recordsize(早期) | ~9–10k | ~37MiB/s | ~26ms | 典型 4K 读放大 + 路径开销 |
和mdadm的性能对比
| 场景 | 4K 随机读 | 4K 随机写 |
|---|---|---|
| /test (sda, 直测) | ~136k IOPS / ~532 MiB/s | ~46.7k IOPS / ~183 MiB/s |
| ZFS mirror (/tank) 冷读取 | ~16k / ~62.6MiB/s | ~1.8k IOPS / ~7 MiB/s |
| ZFS 调参+加CPU后(热读,不具备参考意义) | ~104k IOPS / ~407 MiB/s | – 未测试 |
| mdadm RAID1 + ext4 (/tank on md0) | 151k IOPS / 591 MiB/s | 21.2k IOPS / 82.9 MiB/s(被其中一块盘拖累) |


REK2 搭建6节点K8S教程(四):K8S可视化管理工具
Read Article
REK2 搭建6节点K8S教程(二):HAProxy + Keepalived 高可用
Read Article