
上一节我们讲解了HAProxy + Keepalived高可用技术,本章将介绍RKE2,也称为 RKE Government,RKE2 是一个专注于安全和合规性Kubernetes 发行版,适合企业环境使用。本章将详细介绍如何通过脚本安装 RKE2。
| 节点 | IP/hostname | 系统 |
| VIP(虚拟IP) | 10.88.88.70 | 虚拟IP |
| Master1 | 10.88.88.71/k8sm1 | Ubuntu Server 22.04 LTS |
| Master2 | 10.88.88.72/k8sm2 | Ubuntu Server 22.04 LTS |
| Master3 | 10.88.88.73/k8sm3 | Ubuntu Server 22.04 LTS |
| Worker1 | 10.88.88.74/k8sn1 | Ubuntu Server 22.04 LTS |
| Worker2 | 10.88.88.75/k8sn2 | Ubuntu Server 22.04 LTS |
| ManageNode1 | 10.88.88.76/k8smgt | Ubuntu Server 22.04 LTS |
1.安装RKE2
建议到 https://github.com/rancher/rke2/releases/ 下载最新版本,上传到服务器,或使用本站代理下载。
mkdir /root/rke2-artifacts && cd /root/rke2-artifacts/
curl -OLs http://procoding.oss-cn-shanghai.aliyuncs.com/blog_download/v1.33.1%2Brke2r1/rke2-images.linux-amd64.tar.zst
curl -OLs http://procoding.oss-cn-shanghai.aliyuncs.com/blog_download/v1.33.1%2Brke2r1/rke2.linux-amd64.tar.gz
curl -OLs http://procoding.oss-cn-shanghai.aliyuncs.com/blog_download/v1.33.1%2Brke2r1/sha256sum-amd64.txt
curl -OLs http://procoding.oss-cn-shanghai.aliyuncs.com/blog_download/v1.33.1%2Brke2r1/install.sh 1.1 第一个Master 节点安装
执行安装命令:
INSTALL_RKE2_TYPE="server" INSTALL_RKE2_ARTIFACT_PATH=/root/rke2-artifacts sh install.sh验证安装:
ls /usr/local/bin/
systemctl list-unit-files | grep rke2-server
systemctl list-unit-files | grep rke2-agent.service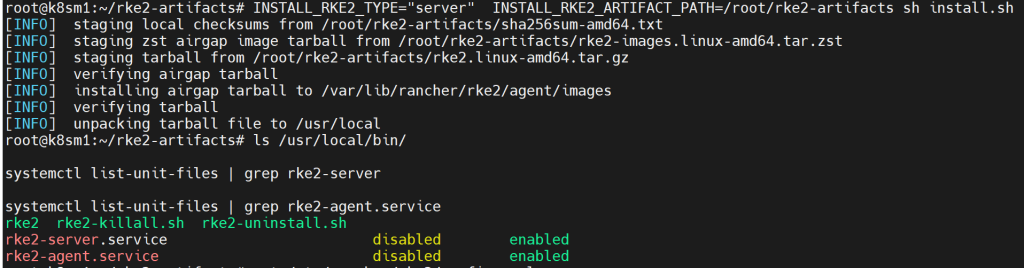
创建配置文件:
需要新建配置文件 /etc/rancher/rke2/config.yaml
sudo mkdir -p /etc/rancher/rke2 && touch /etc/rancher/rke2/config.yaml
sudo vim /etc/rancher/rke2/config.yaml
#config.yaml内容
token: F7knSicWvW29Y98 #集群密钥
tls-san:
- 10.88.88.70 #集群VIP
- 10.88.88.71 #本Master节点
- 127.0.0.1 #本Master节点
# 限制只有关键组件(Critical Addons)才能调度并运行在该节点上,是用于保护关键节点资源的常见做法(工作负载 不允许在该节点上运行)
#node-taint:
# - "CriticalAddonsOnly=true:NoExecute"
配置镜像代理/etc/rancher/rke2/registries.yaml
mirrors:
docker.io:
endpoint:
- "https://hub.procoding.cn/"
启动服务:
## 设置开机启动
systemctl enable rke2-server
#开启服务
systemctl start rke2-server
## 启动过程耗时会比较久:5-10 分钟,
## 启动失败时,可以借助 "rke2 server --config /etc/rancher/rke2/config.yaml --debug" 查看细节
#添加软连接
ln -sf /var/lib/rancher/rke2/bin/kubectl /usr/local/bin/kubectl
echo 'export KUBECONFIG=/etc/rancher/rke2/rke2.yaml' >> ~/.bashrc
source ~/.bashrc
## 检验节点及服务是否正常
kubectl get node
# 获取server token
cat /var/lib/rancher/rke2/server/node-token设置配置:
echo "export PATH=$PATH:/var/lib/rancher/rke2/bin" >> /etc/profile && source /etc/profile
# 重新生成 ~/.kube/config
mkdir -p ~/.kube
cp /etc/rancher/rke2/rke2.yaml ~/.kube/config
chmod 600 ~/.kube/config
#添加配置文件
vim ~/.bashrc
#插入
export KUBECONFIG=/etc/rancher/rke2/rke2.yaml
#保存
source ~/.bashrc1.2 第2/3个Master 节点安装
和第一个master步骤一样,暂时配Server为master1的地址,因为负载均衡和VIP需要master安装完毕才生效,/etc/rancher/rke2/config.yaml 配置需要变为:
server: https://10.88.88.71:9345 #第一个master地址
token: K10fdxxxxx:server:F7knSicWvW29Y98 #从 master1的/var/lib/rancher/rke2/server/node-token获取
#集群密钥
tls-san:
- 10.88.88.70 #集群VIP
- 10.88.88.71 #master1
- 10.88.88.72 #master2
- 127.0.0.1 #本Master节点
# 限制只有关键组件(Critical Addons)才能调度并运行在该节点上,是用于保护关键节点资源的常见做法(工作负载 不允许在该节点上运行)
#node-taint:
# - "CriticalAddonsOnly=true:NoExecute"
#apiserver-port: 93451.3 完成master的安装后,修改三个master的config.yaml为VIP地址
/etc/rancher/rke2/config.yaml 现在可以配置为VIP地址了,这样master三个挂掉2个业务也可以正常运行:
server: https://10.88.88.70:9345 #VIP地址
token: K10fdxxxxx:server:F7knSicWvW29Y98 #从 master1的/var/lib/rancher/rke2/server/node-token获取
tls-san:
- 10.88.88.70 #集群VIP
# 限制只有关键组件(Critical Addons)才能调度并运行在该节点上,是用于保护关键节点资源的常见做法(工作负载 不允许在该节点上运行)
#node-taint:
# - "CriticalAddonsOnly=true:NoExecute"
1.4 Worker节点安装
执行安装命令:
INSTALL_RKE2_TYPE="agent" INSTALL_RKE2_ARTIFACT_PATH=/root/rke2-artifacts sh install.sh配置/etc/rancher/rke2/config.yaml
执行创建文件夹命令:
mkdir -p /etc/rancher/rke2/
vi /etc/rancher/rke2/config.yaml #/etc/rancher/rke2/config.yaml
server: https://10.88.88.70:9345 #VIP地址
token: K10fdxxxxx:server:F7knSicWvW29Y98 #从 master1的/var/lib/rancher/rke2/server/node-token获取
tls-san:
- 10.88.88.70 #集群VIP启动服务
#设置开机启动
systemctl enable rke2-agent
#开启服务
systemctl start rke2-agent1.5 删除对应节点
登录到要删除的节点,执行以下命令
rke2-killall.sh
rke2-uninstall.sh
## 执行删除操作
kubectl delete node {NODE-NAME}1.6 验证安装
执行kubectl get node
kubectl get node
kubectl get pods --all-namespaces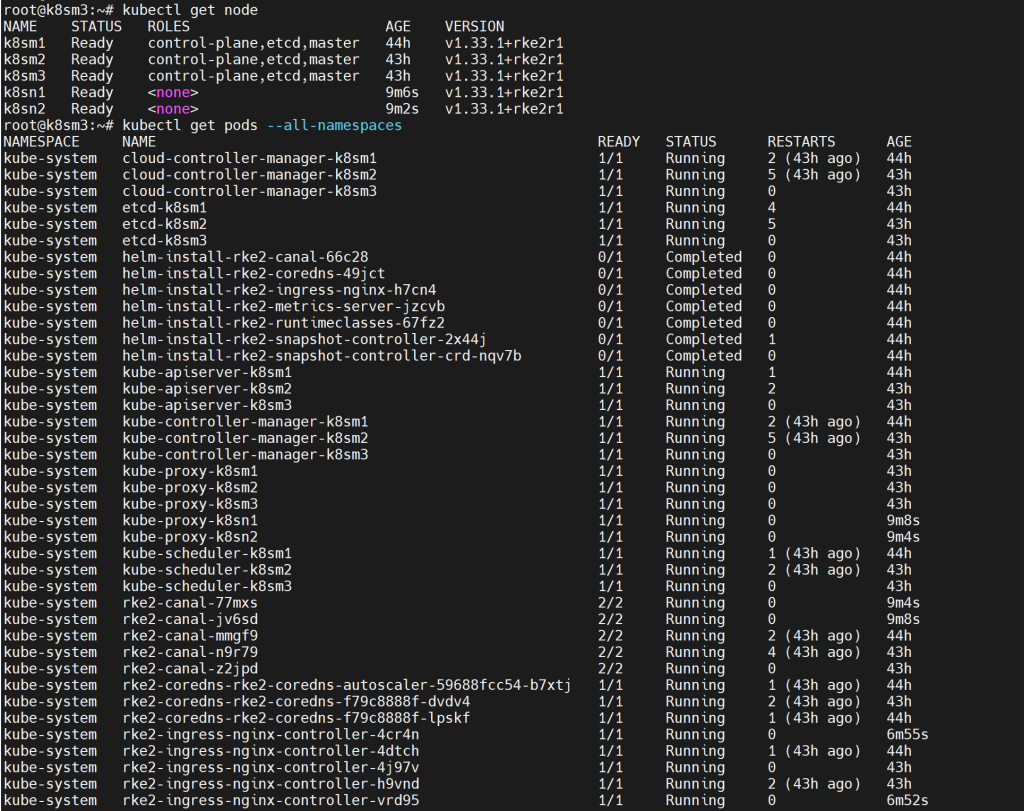
1.7 命令行管理
RKE2 附带了多个 CLI 工具来帮助你访问和调试集群。启动时,它们会被提取到 /var/lib/rancher/rke2/bin。
kubectl
admin kubeconfig 在 /etc/rancher/rke2/rke2.yaml 处生成。
示例:
export KUBECONFIG=/etc/rancher/rke2/rke2.yaml
/var/lib/rancher/rke2/bin/kubectl get nodesContainerd
RKE2 附带了 ctr 和 crictl。Containerd 套接字位于 /run/k3s/containerd/containerd.sock。
示例:
/var/lib/rancher/rke2/bin/ctr --address /run/k3s/containerd/containerd.sock --namespace k8s.io container lsexport CRI_CONFIG_FILE=/var/lib/rancher/rke2/agent/etc/crictl.yaml
/var/lib/rancher/rke2/bin/crictl ps上面一长串用起来太麻烦,执行重定向代码:
export SHELLRC=~/.bashrc;
# 添加 crictl 配置
echo "export CRI_CONFIG_FILE=/var/lib/rancher/rke2/agent/etc/crictl.yaml" >> $SHELLRC && \
echo "✅ 已添加 crictl 配置文件" || echo "⚠️ crictl 配置已存在";
# 添加 RKE2 bin 到 PATH
echo "export PATH=\$$PATH:/var/lib/rancher/rke2/bin/" >> $SHELLRC && \
echo "✅ 已添加 RKE2 bin 到 PATH" || echo "⚠️ PATH 配置已存在";
# 定义 ctr 别名(注意转义单引号)
echo "alias ctr='ctr --address /run/k3s/containerd/containerd.sock --namespace k8s.io'" >> $SHELLRC && \
echo "✅ 已设置 ctr 别名" || echo "⚠️ ctr 别名已存在";
# 立即应用配置
source $SHELLRC && \
echo "✅ 配置已生效!运行 'crictl ps' 和 'ctr container ls' 验证"Helm(可选安装)
sudo apt install git -y
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3
chmod 700 get_helm.sh
sudo ./get_helm.sh2. GPU支持
2.1 安装GPU驱动
首先安装前置项
sudo apt-get -y install g++ gcc make建议禁用系统更新,否则会掉驱动
sudo sed -i 's/1/0/g' /etc/apt/apt.conf.d/10periodic
sudo sed -i 's/1/0/g' /etc/apt/apt.conf.d/20auto-upgrades禁用nouveau 和 Secure Boot:
方法1:/etc/modprobe.d/blacklist.conf 末尾添加如下
blacklist nouveau
options nouveau modeset=0方法2:直接执行下面的代码
#或者
echo "options nvidia NVreg_OpenRmEnableUnsupportedGpus=1" >> /etc/modprobe.d/nvidia.conf
echo "blacklist nouveau" >> /etc/modprobe.d/blacklist-nvidia-nouveau.conf
echo "options nouveau modeset=0" >> /etc/modprobe.d/blacklist-nvidia-nouveau.conf
echo "blacklist microcode" >> /etc/modprobe.d/intel-microcode-blacklist.conf更新并重启系统
update-initramfs -u
reboot验证是否成功关闭,如果没有成功关闭进入BIOS/虚拟机设置页面,找到 Secure Boot 选项,并将其关闭(Disable)。
#检查nouveau 状态
lsmod | grep nouveau
#检查Secure Boot 状态
mokutil --sb-state 查看显卡是否存在
lspci | grep -i nvidia下载显卡驱动(选合适的)
#20250714最新版 cuda 12.9.1
wget https://developer.download.nvidia.com/compute/cuda/12.9.1/local_installers/cuda_12.9.1_575.57.08_linux.run
sudo sh cuda_12.9.1_575.57.08_linux.run如果安装后执行nvidia-smi提示No devices were found,驱动时需要添加-m=kernel-open参数即可,例如:
bash cuda_12.9.1_575.57.08_linux.run -m=kernel-open安装完成后配置系统变量:
cat >> ~/.bashrc <<'EOF'
export CUDA_HOME=/usr/local/cuda
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
EOF
source ~/.bashrc检查是否安装成功
nvidia-smi
nvcc -V安装nvidia-container-runtime 和 nvidia-container-toolkit
老版本:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update \
&& sudo apt-get install -y nvidia-container-toolkit最新版本:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | \
sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -fsSL https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list > /dev/null
sudo apt update
sudo apt install -y nvidia-container-toolkit、2.2 将GPU节点加入集群
如果先安装了nvidia-container-runtime和nvidia-container-toolkit, RKE2会自动添加nvidia runtime到containerd的配置当中。
–执行第本文1.4 Worker节点安装–
安装完成后检查sudo cat /var/lib/rancher/rke2/agent/etc/containerd/config.toml 文件
sudo cat /var/lib/rancher/rke2/agent/etc/containerd/config.toml查看是否包含
[plugins.'io.containerd.cri.v1.runtime'.containerd.runtimes.'nvidia']
runtime_type = "io.containerd.runc.v2"
[plugins.'io.containerd.cri.v1.runtime'.containerd.runtimes.'nvidia'.options]
BinaryName = "/usr/bin/nvidia-container-runtime"
SystemdCgroup = true
[plugins.'io.containerd.cri.v1.images'.registry]
config_path = "/var/lib/rancher/rke2/agent/etc/containerd/certs.d"
2.3 安装 Nvidia GPU Operator(需要首先安装helm,本文1.7节)
帮助你在 Kubernetes 集群中 自动安装、配置和管理 GPU 驱动、插件和监控组件,从而支持基于 GPU 的 AI/深度学习等工作负载。
GPU Operator 的优势
自动化:无需手动安装 NVIDIA 驱动、CUDA 工具包等繁琐步骤。
一致性:在多节点、多环境中保持配置一致。
可扩展性:支持多种 GPU 型号和不同版本的驱动。
监控能力:自动集成 DCGM Exporter,便于 Prometheus 和 Grafana 的 GPU 监控。
兼容性验证:提供 validator 工具确保组件部署无误。
添加nvidia代码库,在master上执行
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \
&& helm repo update安装gpu-operator, 设置不需要自动安装nvidia驱动,在master上执行:
helm upgrade --install gpu-operator \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--set operator.defaultRuntime=containerd \
--set driver.enabled=false \
--set toolkit.enabled=false如果镜像拉不下来,修改镜像地址为registry.k8s.io 改为 k8s.m.daocloud.io
检查是否正确安装,在master上执行:
apt install jq -y
kubectl get node <gpu节点的hostname> -o jsonpath='{.status.allocatable}' | jq返回:
{
"cpu": "8",
"ephemeral-storage": "96292716879",
"hugepages-1Gi": "0",
"hugepages-2Mi": "0",
"memory": "32862000Ki",
"nvidia.com/gpu": "1",
"pods": "110"
}新建pod测试gpu:
gpu-check.yaml
apiVersion: v1
kind: Pod
metadata:
name: gpu-check
namespace: default
spec:
restartPolicy: OnFailure
runtimeClassName: nvidia #这里是重点。
containers:
- name: cuda-container
command:
- /bin/sh
- '-c'
- tail -f /dev/null
image: nvcr.io/nvidia/pytorch:25.06-py3
resources:
limits:
nvidia.com/gpu: 1
env:
- name: NVIDIA_VISIBLE_DEVICES
value: all
- name: NVIDIA_DRIVER_CAPABILITIES
value: compute,utility执行
kubectl apply -f gpu-check.yaml创建成功后,到容器内执行命令:
nvidia-smi
nvcc -V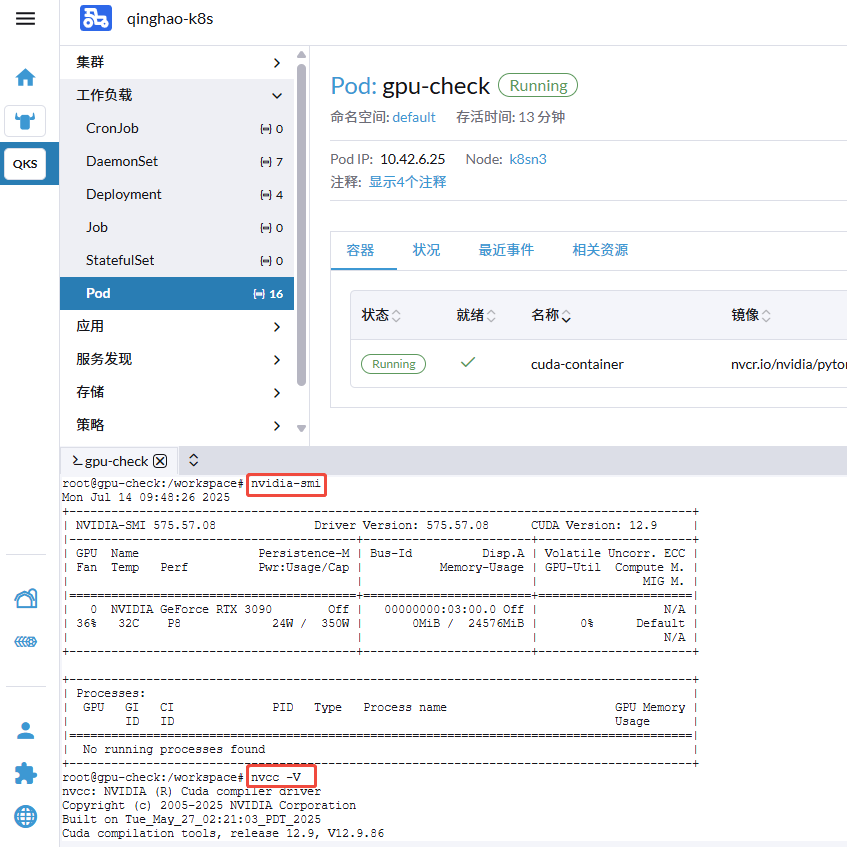
创建一个gpu验证脚本:
gpu-test.py
import torch
import time
cuda_available = torch.cuda.is_available()
print('CUDA版本:',torch.version.cuda)
print('Pytorch版本:',torch.__version__)
print('显卡是否可用:','可用' if(cuda_available) else '不可用')
print('显卡数量:',torch.cuda.device_count())
print('是否支持BF16数字格式:','支持' if (torch.cuda.is_bf16_supported()) else '不支持')
print('当前显卡型号:',torch.cuda.get_device_name())
print('当前显卡的CUDA算力:',torch.cuda.get_device_capability())
print('当前显卡的总显存:',torch.cuda.get_device_properties(0).total_memory/1024/1024/1024,'GB')
print('是否支持TensorCore:','支持' if (torch.cuda.get_device_properties(0).major >= 7) else '不支持')
print('当前显卡的显存使用率:',torch.cuda.memory_allocated(0)/torch.cuda.get_device_properties(0).total_memory*100,'%')
x = torch.randn(3, 3) # 创建一个3x3的随机张量
if cuda_available:
x = x.to('cuda') # 将张量移动到GPU
print("张量GPU移动测试-成功:", x)
else:
print("张量GPU移动测试-失败.")
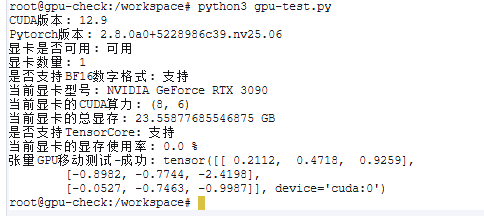
完成。
TODO(20250708):
- 储存卷相关及NFS等待补充。
- helm 相关
本文参考文档:
https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/getting-started.html
https://docs.rke2.io/advanced#deploy-nvidia-operator
K8S命令手记:
- 停止并挂起容器
/bin/sh -c 'tail -f /dev/null'

GitLab CE搭建指南
Read Article
REK2 搭建6节点K8S教程(二):HAProxy + Keepalived 高可用
Read Article
配置k8sm1的步骤中启动服务:## 检验节点及服务是否正常 kubectl get node 会报错应放在设置环境配置步骤之后,建议由systemctl status rke2-server 代替